How Do Large Language Models Generate Text?
Inside the Mechanics of Neural Networks, Transformers, and AI Creativity
Updated on Saturday, October 26, 2024
Table of Contents
- Introduction
- Neural Networks: The Foundation of LLMs
- 2024 Nobel Prize-Winning Contributions to Machine Learning
- LLMs, Neural Networks, and Transformers
- The Role of Temperature in LLM Creativity
- Learning Process and Fine-Tuning
- The Future
1. Introduction
Large Language Models (LLMs) have revolutionized the field of natural language processing and artificial intelligence. These sophisticated AI systems can understand, generate, and manipulate human language with unprecedented accuracy and fluency. In this article, we’ll explore the inner workings of LLMs, from their foundational neural network architecture to the latest advancements in the field.
We’ll begin by examining the basic building blocks of LLMs - neural networks - and how recent Nobel Prize-winning research in physics has contributed to their development. Then, we’ll delve into the specific mechanisms that allow LLMs to predict and generate text, including the crucial role of transformers. We’ll also discuss the concept of “temperature” in language generation and how it affects the creativity and unpredictability of the output.
Finally, we’ll explore the learning process behind these models, including the important step of fine-tuning, which allows LLMs to specialize in specific tasks or domains.
Throughout this article, we’ll provide examples and visual aids to help illustrate these complex concepts. By the end, you’ll have a comprehensive understanding of how Large Language Models work and why they’re such a powerful tool in the world of AI.
2. Neural Networks: The Foundation of LLMs
At the heart of every Large Language Model lies a complex neural network. These artificial neural networks are inspired by the biological neural networks found in animal brains, consisting of interconnected nodes or “neurons” that process and transmit information.
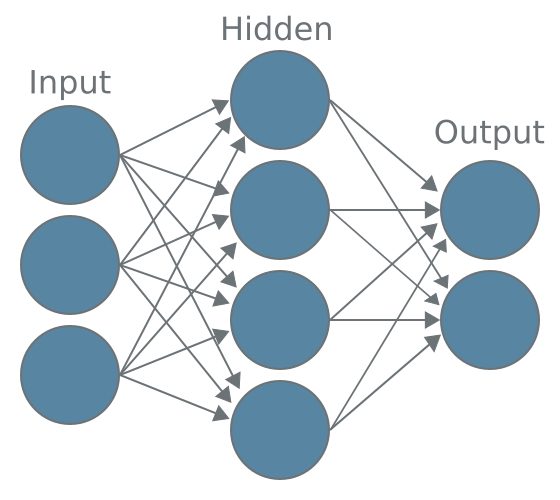
Structure of Neural Networks
A typical neural network consists of three main components:
-
Input Layer: This layer receives the initial data. In the case of LLMs, this could be a sequence of words or tokens.
-
Hidden Layers: These intermediate layers process the information. Deep neural networks, which power LLMs, have many hidden layers, allowing them to learn intricate patterns and representations.
-
Output Layer: This final layer produces the network’s prediction or output.
How Neural Networks Learn
Neural networks learn through a process called backpropagation. Here’s a simplified explanation of how it works:
- The network makes a prediction based on input data.
- The prediction is compared to the actual correct output, and an error is calculated.
- This error is then propagated backwards through the network.
- The weights of the connections between neurons are adjusted to minimize this error.
- This process is repeated many times with large amounts of training data.
Example: Word Prediction
Let’s consider a simple example of how a neural network might learn to predict the next word in a sentence:
Input: “The cat sat on the ____”
The network might learn that after the sequence “The cat sat on the”, the word “mat” often follows. It would adjust its weights to increase the probability of outputting “mat” in this context.
However, LLMs go far beyond this simple example, learning complex patterns and relationships in language that allow them to generate coherent and contextually appropriate text across a wide range of topics and styles.
3. 2024 Nobel Prize-Winning Contributions to Machine Learning
The 2024 Nobel Prize in Physics was awarded to John J. Hopfield and Geoffrey Hinton “for discovering learning algorithms in brain-inspired networks, leading to artificial neural networks and machine learning. their contributions have been fundamental to the development of machine learning and artificial neural networks.
John J. Hopfield’s Contributions
-
Associative Memory: In 1982, Hopfield developed a neural network model known as the Hopfield network, which can store and retrieve patterns, mimicking associative memory in the brain.
-
Energy Landscape Concept: Hopfield described the overall state of the network using a property equivalent to energy in physical systems. This allowed the network to find stored patterns by minimizing energy, similar to a ball rolling into a valley.
-
Pattern Recognition: The Hopfield network can recreate data that contains noise or has been partially erased, making it useful for pattern recognition tasks.
Geoffrey Hinton’s Contributions
-
Boltzmann Machine: In 1985, Hinton and his colleague Terrence Sejnowski developed the Boltzmann machine, which expanded on Hopfield’s work using concepts from statistical physics.
-
Unsupervised Learning: The Boltzmann machine can learn from examples without explicit instructions, making it an early example of unsupervised learning in neural networks.
-
Deep Learning Foundations: In 2006, Hinton and his colleagues developed a method for pretraining neural networks using stacked Boltzmann machines, which laid the groundwork for deep learning techniques.
Impact on Machine Learning and AI
-
Foundation for Modern AI: The work of Hopfield and Hinton in the 1980s helped lay the foundation for the machine learning revolution that started around 2010.
-
Inspiration from Physics: Both researchers drew inspiration from physics concepts, such as spin systems and statistical mechanics, to develop their neural network models.
-
Scaling to Modern Systems: While early networks had only a few hundred parameters, their work has scaled to modern language models with over a trillion parameters.
-
Applications in Various Fields: The principles developed by Hopfield and Hinton have found applications in various fields, including image recognition, natural language processing, and even in physics research itself.
The contributions of Hopfield and Hinton demonstrate how fundamental research in physics and interdisciplinary approaches can lead to groundbreaking developments in artificial intelligence and machine learning. Their work continues to influence the development of AI systems that are transforming various aspects of science, technology, and daily life.
4. LLMs, Neural Networks, and Transformers
Large Language Models (LLMs) leverage advanced neural network architectures, particularly transformers, to process and generate human-like text. Let’s explore how these components work together.
Neural Networks in LLMs
LLMs use deep neural networks with billions of parameters. These networks are trained on vast amounts of text data, learning to predict the next word in a sequence given the previous words. The key aspects of neural networks in LLMs include:
- Embeddings: Words are converted into high-dimensional vector representations that capture semantic meanings.
- Hidden Layers: Multiple layers process the input, extracting increasingly abstract features.
- Attention Mechanisms: These allow the model to focus on relevant parts of the input when making predictions.
Transformers: The Game-Changer
Transformers, introduced in the paper “Attention Is All You Need” (Vaswani et al., 2017), revolutionized natural language processing. Key features of transformers include:
-
Self-Attention: This mechanism allows the model to weigh the importance of different words in the input when processing each word, capturing long-range dependencies effectively.
-
Positional Encoding: Since transformers process input in parallel rather than sequentially, positional encodings are added to give the model information about the order of words.
-
Multi-Head Attention: This allows the model to focus on different aspects of the input simultaneously, capturing various types of relationships between words.
How LLMs Generate Text
LLMs generate text through a process called autoregressive generation. Here’s a simplified step-by-step explanation:
- The model takes an input prompt (e.g., “The cat sat on the”).
- It processes this input through its layers, applying self-attention and feed-forward operations.
- The model outputs a probability distribution over its entire vocabulary for the next word.
- A word is chosen from this distribution (we’ll discuss how in the next section on temperature).
- This chosen word is appended to the input, and the process repeats from step 2.
Example: Text Generation
Let’s say we’re using a small LLM to generate text. Given the prompt “The cat sat”, the process might look like this:
- Input: “The cat sat”
- Model processes input
- Output distribution: {“on”: 0.5, “under”: 0.2, “beside”: 0.2, “happily”: 0.1}
- Chosen word: “on” (highest probability)
- New input: “The cat sat on”
- Repeat process…
This process continues until the model generates a stop token or reaches a specified length limit.
By leveraging the power of neural networks and the efficient architecture of transformers, LLMs can generate coherent and contextually appropriate text across a wide range of topics and styles.
5. The Role of Temperature in LLM Creativity
In the context of Large Language Models, “temperature” is a hyperparameter that controls the randomness of the model’s output. This concept is crucial for understanding how LLMs can generate diverse and creative text while maintaining coherence and relevance.
Understanding Temperature
Temperature is typically a value between 0 and 1, though some implementations allow for higher values. Here’s how it affects the text generation process:
-
Low Temperature (close to 0):
- The model becomes more deterministic.
- It tends to choose words with the highest probability.
- Output is more focused, consistent, and potentially repetitive.
-
High Temperature (close to 1 or higher):
- The model becomes more random.
- It’s more likely to choose lower-probability words.
- Output is more diverse, creative, and potentially less coherent.
How Temperature Works
When an LLM generates text, it produces a probability distribution over its entire vocabulary for each word it needs to output. The temperature parameter modifies this distribution before a word is chosen.
Mathematically, this is often implemented using the following formula:
P(w_i) = exp(log(p_i) / T) / Σ exp(log(p_j) / T)
Where:
- P(w_i) is the adjusted probability of word i
- p_i is the original probability of word i
- T is the temperature
- The sum in the denominator is over all words in the vocabulary
Example: Temperature in Action
Let’s consider a simplified example where an LLM is predicting the next word in the phrase “The cat sat on the ____“.
Original probabilities:
- “mat”: 0.6
- “chair”: 0.3
- “moon”: 0.1
With a low temperature (T = 0.1):
- “mat”: 0.99
- “chair”: 0.01
- “moon”: 0.00
With a high temperature (T = 2.0):
- “mat”: 0.40
- “chair”: 0.35
- “moon”: 0.25
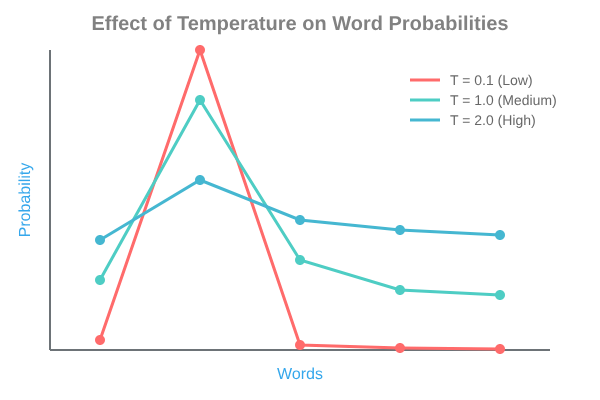
As we can see, lower temperatures amplify the differences between probabilities, making high-probability words even more likely. Higher temperatures flatten the distribution, giving lower-probability words a better chance of being selected.
Creative Applications
By adjusting the temperature, users can control the balance between creativity and coherence in the LLM’s output:
-
Factual Writing: For tasks requiring accuracy and consistency, like generating reports or answering factual questions, a lower temperature is often preferred.
-
Creative Writing: For tasks like storytelling, poetry, or brainstorming, a higher temperature can produce more diverse and unexpected results.
-
Conversational AI: In chatbots or dialogue systems, a moderate temperature can help maintain a balance between staying on-topic and introducing variety into the conversation.
-
Code Generation: When generating code, a lower temperature might be used to stick closely to common patterns, while a slightly higher temperature could be used to generate more creative solutions.
Understanding and effectively using temperature allows users to fine-tune the output of LLMs for specific applications, balancing the trade-off between predictability and creativity as needed for each task.
6. Learning Process and Fine-Tuning
The power of Large Language Models lies in their ability to learn from vast amounts of data and adapt to specific tasks. This section will explore the learning process of LLMs and the importance of fine-tuning.
Pre-training: The Foundation of LLMs
Pre-training is the initial phase of creating an LLM, where the model learns general language understanding and generation capabilities.
-
Data Collection: Massive datasets of text from diverse sources (books, websites, articles) are compiled.
-
Tokenization: Text is broken down into tokens (words or subwords) that the model can process.
-
Unsupervised Learning: The model is trained to predict the next token given the previous tokens, learning patterns and relationships in language.
-
Objective Function: Typically, the model uses a variant of the “masked language model” objective, where it tries to predict masked (hidden) words in a sentence.
-
Optimization: The model’s parameters are adjusted using techniques like stochastic gradient descent to minimize prediction errors.
Fine-tuning: Specializing the Model
After pre-training, LLMs can be fine-tuned for specific tasks or domains. This process adapts the pre-trained model to perform well on particular applications.
-
Task-specific Data: A smaller dataset relevant to the target task is prepared.
-
Transfer Learning: The pre-trained model’s knowledge is transferred and adapted to the new task.
-
Supervised Learning: Unlike pre-training, fine-tuning often involves supervised learning, where the model learns from labeled examples.
-
Careful Optimization: Learning rates are typically lower than in pre-training to avoid catastrophic forgetting of pre-trained knowledge.
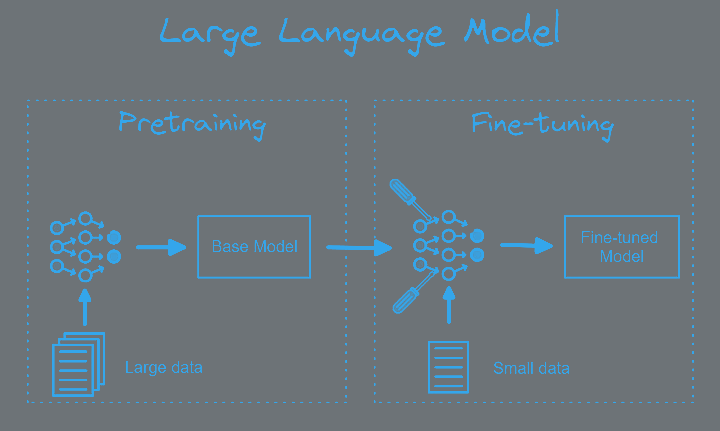
image inspired from Fine-Tune Large Language Model in a Colab Notebook
Example: Fine-tuning for Sentiment Analysis
Let’s consider fine-tuning a pre-trained LLM for sentiment analysis of movie reviews:
-
Pre-trained LLM: Start with a model trained on general text data.
-
Fine-tuning Data: Prepare a dataset of movie reviews labeled as positive or negative.
-
Task Adaptation: Modify the model’s output layer to produce sentiment classifications.
-
Training: Feed movie reviews through the model, compare its predictions to true labels, and adjust parameters to improve accuracy.
-
Evaluation: Test the fine-tuned model on a held-out set of reviews to assess performance.
Advanced Fine-tuning Techniques
-
Few-shot Learning: Fine-tuning with very small amounts of labeled data, leveraging the model’s pre-trained knowledge.
-
Prompt Engineering: Crafting effective prompts to guide the model’s behavior without changing its parameters.
-
Parameter-Efficient Fine-tuning: Techniques like adapter layers or LoRA (Low-Rank Adaptation) that fine-tune only a small subset of the model’s parameters.
-
Continual Learning: Methods to fine-tune models on new tasks without forgetting previously learned tasks.
Ethical Considerations in Learning and Fine-tuning
-
Data Bias: The data used for pre-training and fine-tuning can introduce or amplify biases in the model’s outputs.
-
Privacy Concerns: Ensuring that the model doesn’t memorize and reproduce sensitive information from its training data.
-
Transparency: The complexity of LLMs can make it challenging to understand how they arrive at their outputs.
-
Responsible Deployment: Considering the potential impacts of deploying fine-tuned models in real-world applications.
The learning process and fine-tuning are critical to the development and application of LLMs. By understanding these processes, researchers and practitioners can create more effective, efficient, and responsible AI systems that can adapt to a wide range of language tasks and domains.
6. The Future
In conclusion, the journey of Large Language Models, from their neural network foundations to the innovative use of transformers and fine-tuning techniques, demonstrates the incredible advancements in AI over the past few decades. These models have transformed the way we interact with technology, making it possible to generate human-like text, conduct sophisticated analyses, and support a variety of applications across industries.
The role of temperature settings, pre-training, and task-specific fine-tuning highlights the versatility and adaptability of LLMs, allowing for a balance between creativity and coherence tailored to specific needs. However, as we continue to push the boundaries of what these models can do, it’s essential to remain mindful of the ethical implications, including data bias, privacy, and responsible usage.
As we look to the future, the open-source movement and ongoing research promise to drive further innovation, making these powerful tools more accessible and versatile than ever. By understanding the underlying mechanisms of LLMs, we can better appreciate their potential and responsibly harness their capabilities to create a more intelligent and connected world.